CSOPESY_processes_05 - Scheduling Non-Preemptive, Priority Scheduling, Multilevel Queue, Thread, Multiprocessor
5 Scheduling Criteria
- goal of CPU scheduling is to maximize and minimize certain criteria
- Maximize (you want a high value for these)
- CPU utilization: keep the CPU as busy as possible (range from 0 to 100%)
- throughput: the number of processes completed per time unit
- Minimize (you want to have a low value for these)
- Turnaround Time: the total time from submission to completion (includes waiting in queues, execution, and I/O)
- Waiting Time: the total time a process spends waiting in the ready queue
- Response Time: in an interactive system, the time from submission of a request until the first response is produced (time to start responding, not time to complete)
Scheduling Algorithm Non-Preemptive
First Come First Served
whatever arrives first completes before anything else
- operation: the process that requests the CPU first is allocated the CPU first.
- implemented with a FIFO queue
- performance: simple but can result in poor performance
- convoy effect: if a single long CPU-bound process arrives first, it can block all short processes behind it, leading to low CPU and device utilization


- these are actually worst case scenarios
- if P2 goes first, then P1, then P3 (0 + 3 + 27) /3= 10ms average wait time; it's very variable depending on which process comes in first
Shortest Job first
- Operation: allocates the CPU to the process that has the smallest next CPU burst time
- if the job is short, it gets loaded first
- Optimality: provably optimal, giving the minimum average waiting time for a given set of processes
- Implementation Challenge: difficult to implement in short-term scheduling because predicting the length of the next CPU burst is impossible
- it's not easy to predict the length of the next CPU burst, it's impossible
- short code does not ensure that the processing time is fast
- Approximation: schedulers typically use exponential average prediction based on past burst history to estimate the next burst length

Exponential Average
just use the formula
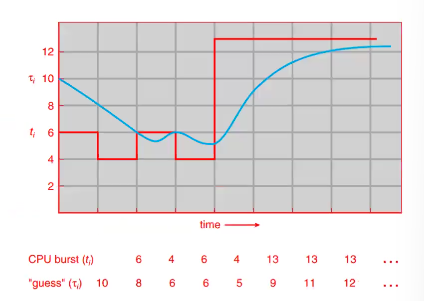
- τ is the tau symbol
- let t_n be the length of the nth CPU burst → meaning this is the actual current CPU burst
- let τ_(n+1) be our predicted value for the next CPU burst
- for α, 0 ≤ α ≤ 1

showing its a weighted formula:
so how do we compute?

note: the next actual CPU burst is 4...
There are other scheduling algorithms that are pre-emptive
Shortest Remaining Time First or Pre-emptive Shortest Job First
NOTE: THIS IS PREEMPTIVE
always chooses the process with the shortest remaining time for completion
- Operation: The preemptive version of SJF. if a new process arrives with a CPU burst shorter than the time remaining on the currently executing process, the current process is preempted.
- Behavior: the scheduler always chooses the process with the shortest remaining time to completion
- Advantage: can significantly decrease the average waiting time compared to non-preemptive SJF, especially for short, incoming jobs
- non-preemptive: waits for the previous process to finish before giving it to the next one
- assumes all the processes come at different times
Preemptive means that the operating system’s scheduler can interrupt (or stop) a currently running process in order to give the CPU to another process that has higher priority (or a shorter burst time, depending on the scheduling algorithm).
Neso Academy SJF: https://www.youtube.com/watch?v=lpM14aWgl3Q
whiteboard at 30:51
34:10

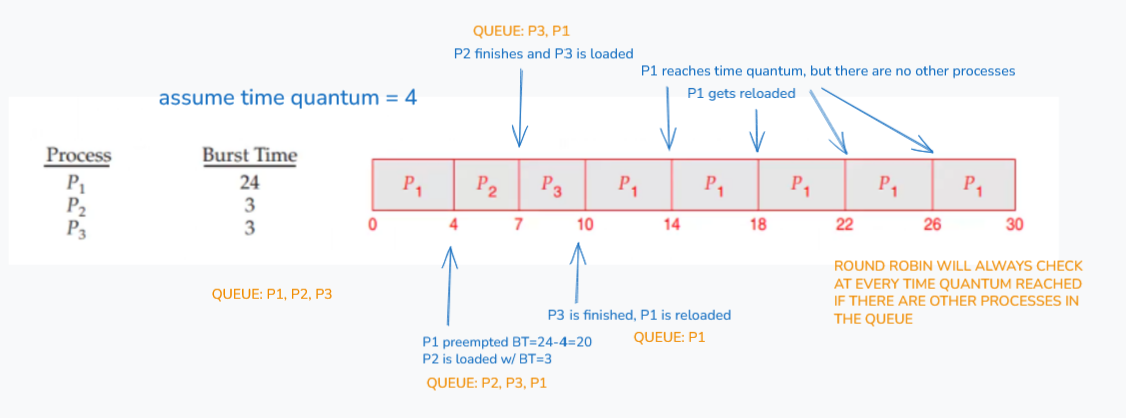
Round Robin
- Operation: designed for time-sharing systems. processes are placed in a FIFO ready queue. the CPU scheduler goes around the queue, allocating the CPU to each process for a small time unit called a time quantum/time slice
- Preemption: if the process does not finish within the time quantum, it is preempted and put back at the tail of the ready queue
- Performance: the time quantum can affect the behavior of the round robin
- Large time quantum - behaves like FCFS
- Small time quantum - high overhead (too many context switches)
- Trade-off: quantum size must be balanced to minimize overhead while ensuring good response time
- rephrase: you have to balance the TQ so ensure that there's good response time but also minimize overhead switching
Priority Scheduling
- Operation: Each process is assigned a priority number, and the CPU is allocated to the process with the highest priority (the smallest integer usually represents the highest priority)
- Preemptive vs Non-preemptive: Can be implemented as both; Preemptive Priority Scheduling will preempt the running process if a higher-priority process arrives
- Problem: Starvation (Indefinite Blocking) - low-priority processes may never execute if a steady stream of high-priority processes exist
- Solution: Aging - gradually increases the priority of processes that wait in the system for a long time, preventing starvation

45:08
Priority Scheduling with Round Robin

Time Quantum TQ=2
- at T=0, P4 has priority 1, executes for BT=7
- at T=0+7=7, P2 and P3 have priority 1, P2 executes w/ BT=5-TQ
so BT=5-2=3 - at T=7+2=9, P2 is preempted, P3 executes w/ BT=8-2=6
- at T=9+2=11, P3 is preempted, P2 resumes w/ BT=3-2=1
- at T=11+2=13, P2 is preempted, P3 resumes w/ BT=6-2=4
- at T=13+2=15, P3 is preempted, P2 finishes w/ BT=1
- at T=15+1=16, P2 is done so P3 resumes w/ BT=4
- at T=16+4=20, P3 finishes and move on to P1 and P5 w/ priority 3
at T=20, P1 executes w/ BT=4 - at T=20+2=22, P1 is preempted w/ BT=4-2=2, P5 executes w/ BT=3
- at T=22+2=24, P5 is preempted w/ BT=3-2=1, P1 resumes w/ BT=2
- at T=24+2=26, P1 finishes execution w/ BT=2-2=0, P5 resumes and finishes
Multilevel Queue and Multilevel Feedback Queue
Multilevel Queue Scheduling
each can have their own priority and scheduling algorithm
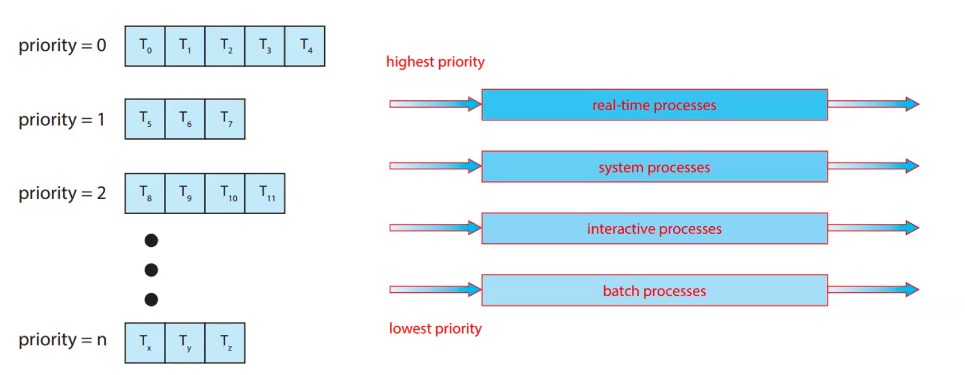
- Concept: divides the ready queue into separate queues based on process characteristics (e.g. foreground/interactive, background/batch)
- Queue priority: each queue has its own scheduling algorithm (e.g. foreground queue might use RR/Round Robin, background might use FCFS)
- BUT Scheduling between queues: fixed-priority preemptive scheduling is often used (e.g. always execute jobs from the foreground queue unless its empty)
- can lead to starvation of lower-priority queues (aka queue with higher priority is always first, the next priority will only be run if the higher one is empty)
- batch processes has the lowest priority
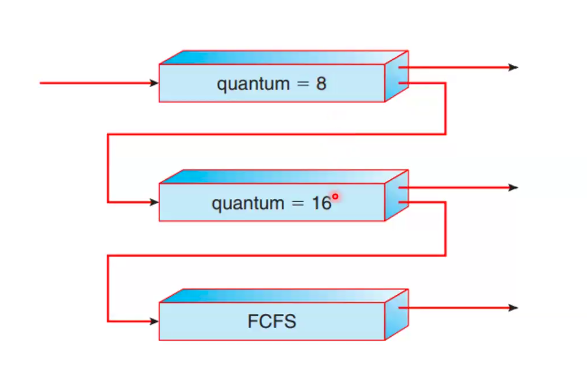
Multi-level Feedback Queue (MLFQ)
- Concept: (what's different is that it) allows a process to move between different queues based on its behavior.
- prevents starvation and separates processes by CPU-burst characteristics
- Mechanism
- a process that uses too much CPU time is moved to a lower-priority queue (penalizing CPU-bound processes)
- a process that waits too long in a low-priority queue can be moved to a higher priority queue (implementing aging to prevent starvation)
- Advantage: MLFQ is the most general and flexible scheduling algorithm.
- configurable by defining parameters like the number of queues, the scheduling algorithm for each queue, and the criteria for moving processes between queues
Multilevel feedback queue mechanism
Thread Scheduling
- Difference from Process Scheduling: scheduling threads is the same as scheduling processes but the scope of scheduling must be considered
- Contention Scope
- Process-Contention Scope (PCS): a scheduler decides which user-level thread to run on an available Lightweight Process (LWP), which is internal to the process
- typical of Many-to-One and Many-to-Many methods
- System-Contention Scope (SCS): the OS kernel scheduler decides which kernel-level thread to run on an available CPU
- typical of One-to-One models and is how modern OS kernels schedule processes
- Process-Contention Scope (PCS): a scheduler decides which user-level thread to run on an available Lightweight Process (LWP), which is internal to the process
user level is PCS
kernel level is SCS
Multi-Processor Scheduling
- Homogeneous Processors: all processors are identical in terms of function and speed
- allows any process in the Ready Queue to run on ANY processor
- Load Sharing: the Ready Queue must be shared among all processors to distribute the workload evenly
- Asymmetric Multiprocessing: only one processor (the master server) handles all scheduling decisions, I/O and other kernel activities
- Symmetric Multiprocessing (SMP): each processor is self-scheduling.
- all processes are in a common Ready Queue (or each CPU has its own private queue), and each processor selects a process to run
- it's common bc it's all the same
- Processor Affinity: most SMP systems try to avoid migrating a process from one processor to another because of the cost of invalidating and reloading the cache memory of the new processor
- its hard to move processes from one core to another because it might reload the cache/memory of the new processor
- Soft Affinity: the OS tries to keep the process on the same processor but doesn't guarantee it
- Hard Affinity: the process can specify that it should not be moved from its current processor; once it's in a processor you cant move it na
OS Examples

Summary

Exercise 1 CPU Scheduling: FCFS and SJF
42/44 but might be an encoding error

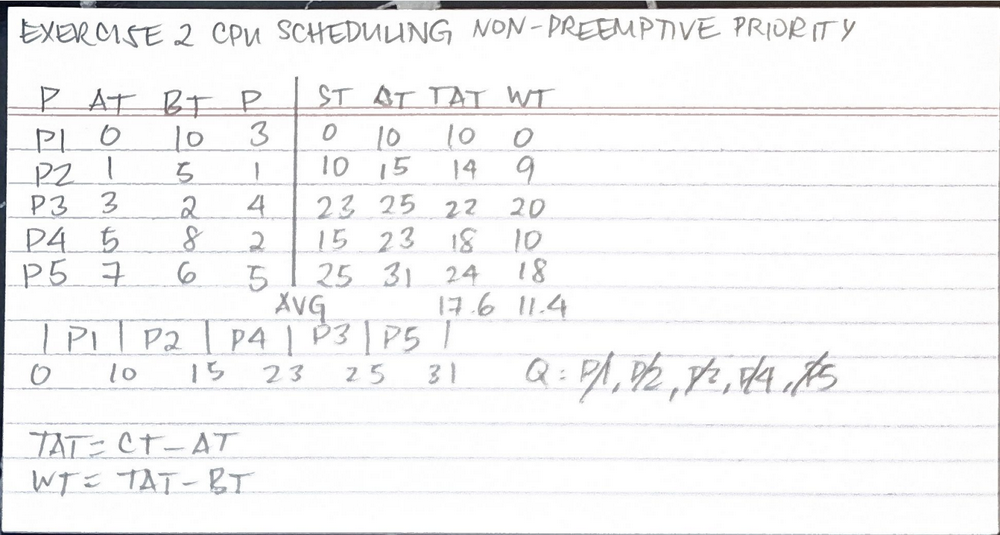
Exercise 2 CPU Scheduling: Non-Preemptive Priority & Preemptive Shortest Remaining Time First (SRTF) Scheduling
44/44

Exercise 3 Round Robin
17/22
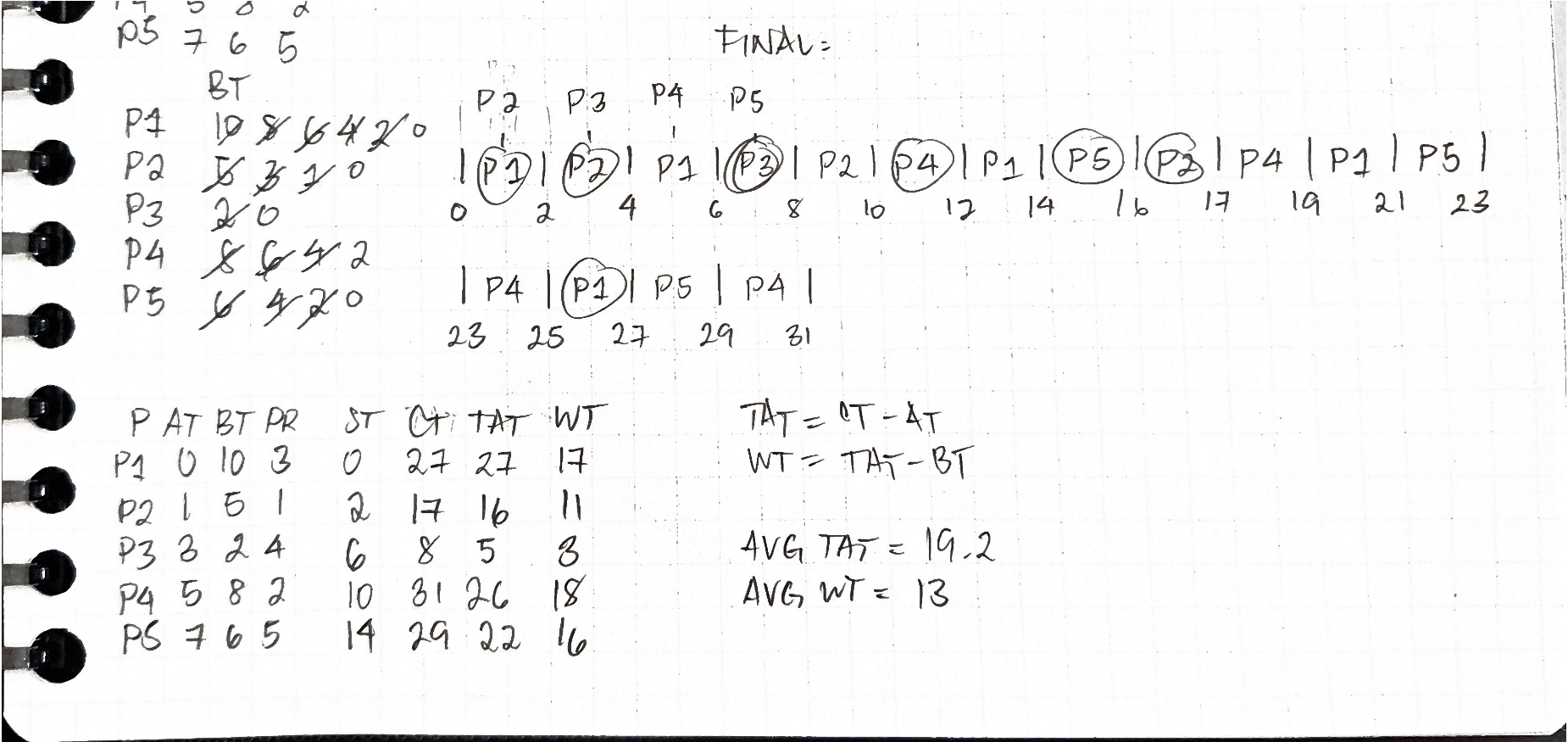
ANS in parentheses if wrong
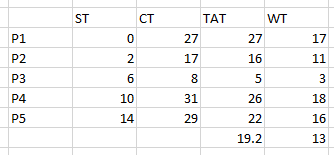
| P | ST | CT | TAT | WT |
|---|---|---|---|---|
| P1 | 0 | 27 | 27 | 17 |
| P2 | 2 | 17 | 16 | 11 |
| P3 | 6 | 8 | 5 | 3 |
| P4 | 10 | 31 | 26 | 18 |
| P5 | 14 | 29 | 22 | 16 |
| AVG | 19.2 | 13 | ||
| ans key says P2 CT = 27 and P2 TAT = 27 and P2 WT = 17 | ||||
| but if the CT of P2 = 27 | ||||
| and TAT=CT-AT, | ||||
| P2 CT = 27 ("answer") | ||||
| P2 AT = 1 (given) | ||||
| P2 TAT = 27-1 = 26 which isn't in the "answer" |
Update: mine was correct